
27、缓存:进程内缓存要怎么玩?
- no27:什么是进程内缓存?好处?不足?
- 定义
- 将数据缓存在站点或者服务的进程内,如 map 或 leveldb,可存 json、html、object 等
- 好处
- 1.节省内网带宽
- 2.时延更低
- 不足:一致性难以保证
- 定义
- no27:如何保证进程内缓存的一致性?
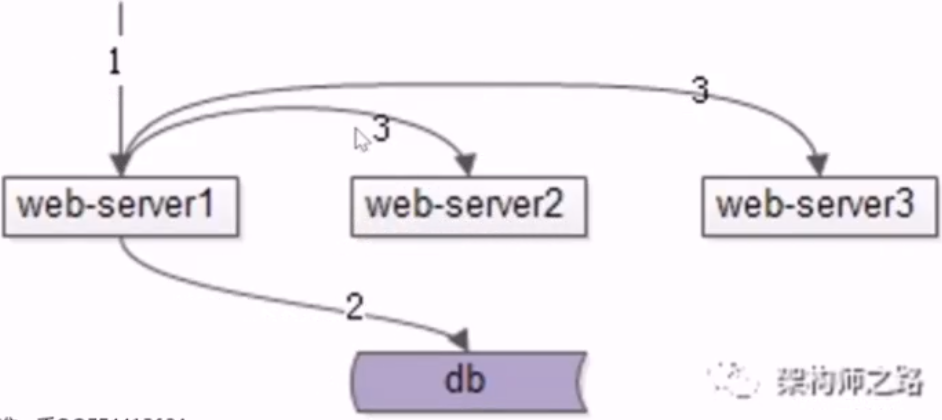
- 方案一,单节点通知其它节点
- 缺点
- 同一功能在集群内的多个节点相互耦合在一起,当节点比较多的时候,连接关系会相对比较复杂
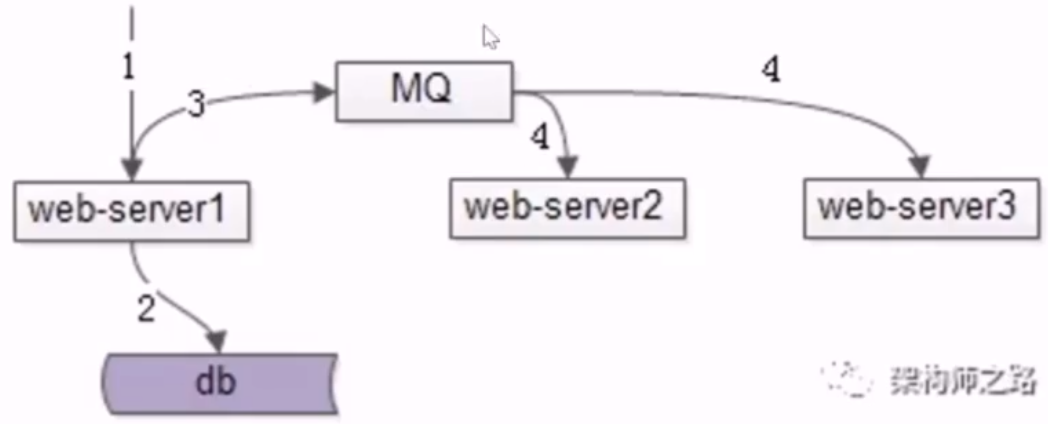
- 方案二,MQ 解耦,通知其它节点
- 缺点
- 接触了结点耦合,但引入了 mq,增加系统复杂度
- 方案三,放弃实时一致性,定期从后端更新数据

- 缺点
- 必须一定程度上接受读旧数据
- 方案一,单节点通知其它节点
- no27:使用进程内缓存的场景是哪些?为什么不能频繁使用进程内缓存?
- 场景
- 1.只读数据
- 2.并发极高,透传后端压力极大
- 3.允许一定程度上数据不一致
- 原因
- 违背了「站点无状态、服务无状态」的设计准则
- 场景
28、缓存:很多时候我们都用错了!
- no28:缓存有哪 4 种误用的情况?
- 1.服务与服务之间不要通过缓存传递数据,数据传递使用 MQ 更合适
- 2.如果缓存挂掉,可能导致雪崩,此时要做高可用缓存,或者水平切分
- 3.调用方不宜再单独使用缓存存储服务底层的数据,容易出现数据不一致,以及反向依赖.
- 4.不同服务,缓存实例要做垂直拆分,不宜共用缓存
- 1.服务与服务之间不要通过缓存传递数据,数据传递使用 MQ 更合适


29、缓存:互联网最佳实践!
- no29:互联网缓存最佳实践 Cache Aside Pattern 是什么?
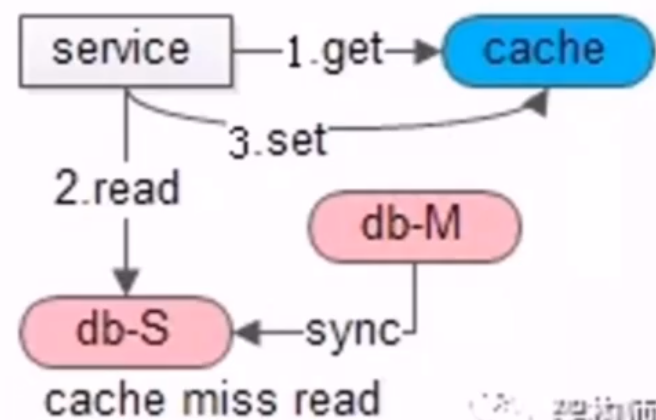
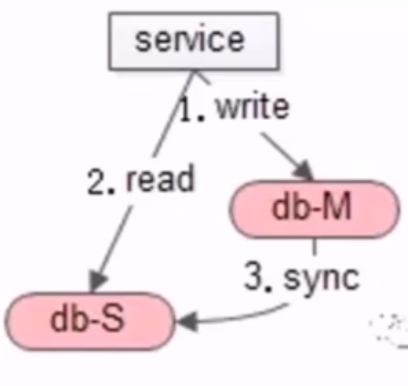
- 读实践
- 先缓存,命中返回,未命中读数据库,再设置缓存
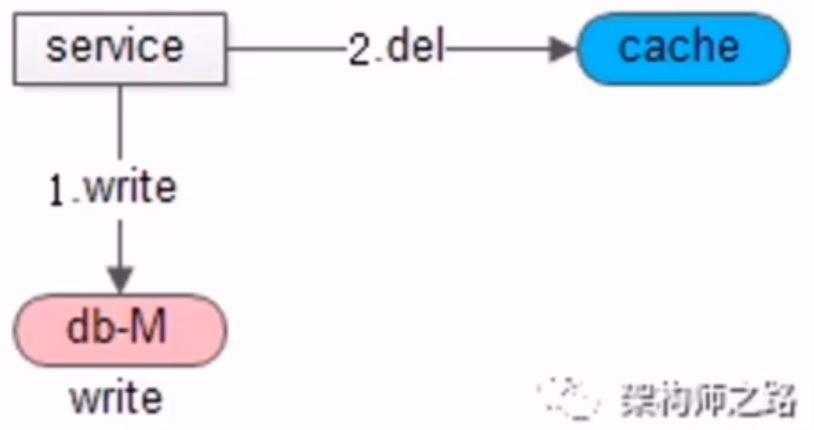
- 写实践
- 淘汰缓存而不是修改缓存,先操作数据库,而不是先淘汰缓存
- 读实践
30、缓存:一致性优化!
- no30:数据库主从、数据库缓存什么时候会发生数据不一致问题?
- 数据库主从:写后立即读,短时间内,读旧数据
- 数据库缓存:写后立即读,短时间内,旧数据入缓存
- 数据库主从:写后立即读,短时间内,读旧数据
- no30:缓存不一致的优化思路和两个方案是什么?
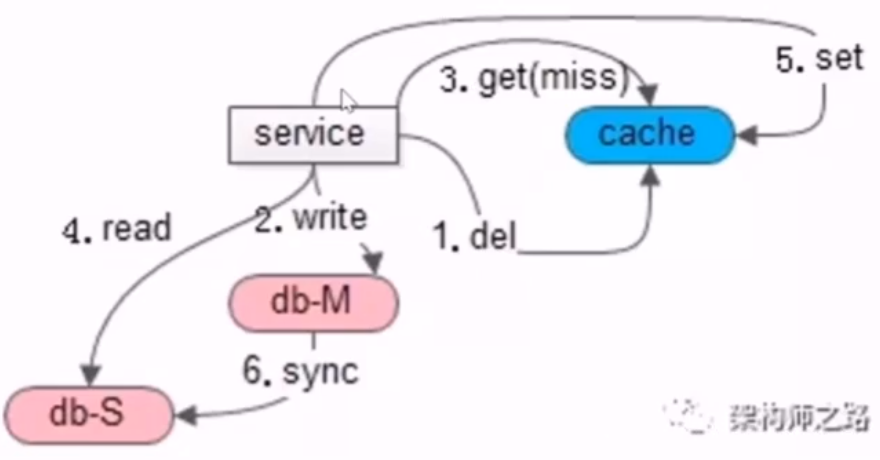
- 思路:在从库同步完成之后,如果有旧数据入缓存,应该及时把这个旧数据淘汰掉
- 方案一:二次淘汰法(在从库异步淘汰,或服务中异步淘汰)
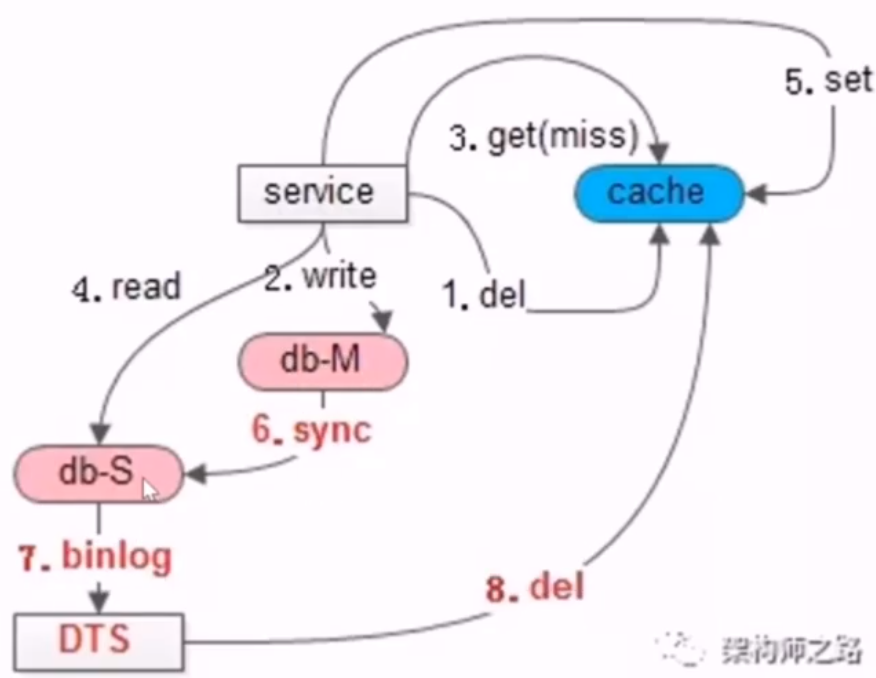
- 通过工具订阅从库的 binlog,如 DTS 或 canal,或自己订阅和分析 binlog,然后从库执行异步淘汰缓存的操作
- 方案二:为允许 cache miss 的场景,设定超时时间
31、缓存:并发更新的大坑!
- no31:缓存并发更新获取 token 会出现什么问题?如何解决?
- 问题
- 两个并发请求的token申请,可能导致 token 迭代过期了
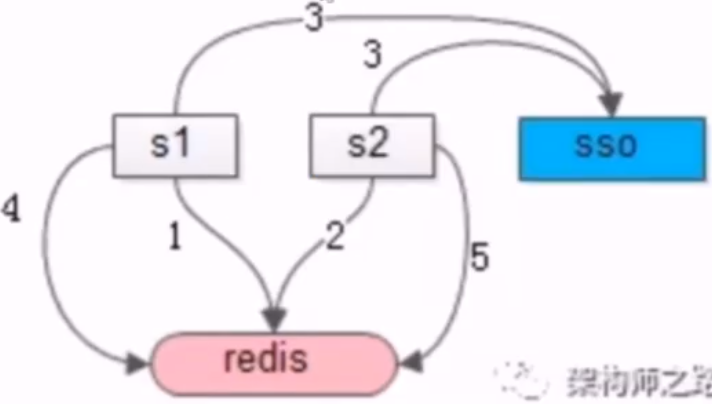
- 解决
- 线上服务 s1 和 s2 只从缓存中读取 token,token 的更新由一个异步的服务 asy-Master 定期更新,避免并发的更新
- 缺点
- 读取服务和更新的服务会直接调用缓存实例,如果缓存实例变更,读的服务和写的服务配置同步变更,导致耦合,违背了两个服务不应访问同一服务的通用性原则,同时违反了 cache aside pattern 的淘汰而不是更新缓存的设计准则
- 数据存储在 DB,缓存应该淘汰,有时候,数据不在数据库,缓存需要更新,如调用第三方服务需要申请 token
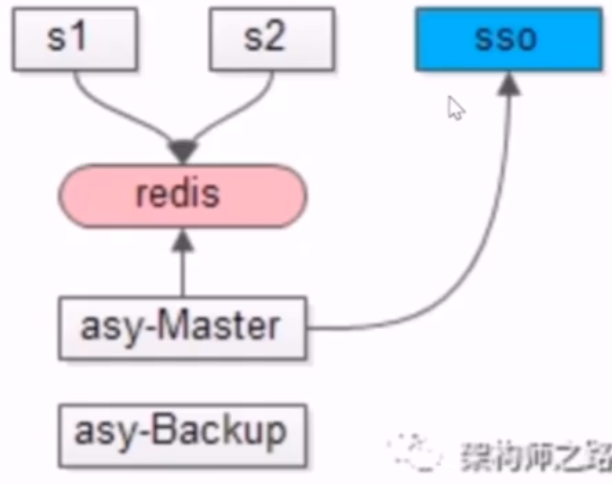
- 问题
32、缓存:究竟选redis,还是memcache?
- no32,什么时候选 Redis,什么时候选 memcache?
- 选 Redis
- 1.复杂数据结构
- 2.持久化
- 优点是,缓存挂了再重启,可以快速恢复,不需要 cache 的预热功能
- 但不建议使用,因为可能会导致缓存和数据库不一致
- 3.天然高可用,支持主从复制,读写分离,提供了 sentinel 的集群管理工具,能够实现主从服务的监控,故障自动转移,mc 需要二次开发,但绝大多数缓存不需要做高可用
- 4.存储内容比较大,mc 的 kv 存储的 value 最大只支持 1M
- 选 memcache
- 纯 kv
- 原因:
- 1.预分配内存池
- 2.redis 的 VM 机制更慢
- 3.redis 的 CPU 计算复杂
- 4.多线程可利用多核
- 其它
- 1.redis 源码可读性好
- 2.redis 和 mc 都需要手动水平切分
- 选 Redis